Remote-debugging the Gracious Host
2024-11-29 MSK 014 math digital
The MSK 014 Gracious Host is meant to work with all standards-compliant USB MIDI devices, but that's often easier said than done. I had some adventures recently when I helped a customer get the Gracious Host running with a Teenage Engineering OP-1 (original, not "Field"), and it makes for a good story.
In general, I don't promise to put in heroic efforts to ensure compatibility with any particular device that I didn't test myself while developing the Gracious Host firmware. There are so many things that can go wrong with USB connections that sometimes I think it's amazing USB works at all, and when the host module is DIY as well (which this one was), it's nearly impossible to give any guarantees. I also have a bit of a feeling that I shouldn't throw good money after bad: the MSK 014 hasn't sold enough to pay for its (significant) development costs, it probably never will, and so it's hard to spend more development time, which costs money, on continued support of its firmware.
But the OP-1 is a popular synthesizer - if this customer wanted to connect one to an MSK 014, then so will others. And the more I learned about the OP-1's USB connection, the clearer it seemed that it really ought to work with the Gracious Host. The OP-1 is just a standard, class-compliant USB MIDI device. The Gracious Host is supposed to work with those. So why wasn't it just simply working, when the customer plugged it in?
Hosts, devices, and "On The Go"
Pieces of equipment that speak USB protocols can be divided into "hosts" and "devices." Hosts are basically computers. Hosts provide power to the bus and act as bus masters. Devices are things that plug into hosts - such as keyboards, mice, cameras, and so on. In general, the devices receive power, and they take orders from the masters. There needs to be exactly one host on the bus, but there may be multiple devices. There are often "hubs" in between the host and the devices, allowing connection of multiple devices to the same host USB port, and sometimes there's even more than one layer of hubs.
The host/device distinction often confuses people when they want to use USB to carry MIDI signals because unlike USB, MIDI is conceptually peer to peer and people expect all MIDI equipment to be compatible. If you have a typical Eurorack USB-MIDI interface module like a Doepfer A-190-3, and a typical USB-MIDI music keyboard, guess what? They're both "devices" and they won't talk to each other directly. They each need to connect to a host. Other Eurorack modules exist that can function as hosts for USB devices; and that's what the Gracious Host does. But the Gracious Host can only be a host; it will not connect to another host like itself.
When my customer contacted me asking for help connecting the OP-1, his first thought for why it wasn't working, was the same as mine: maybe the OP-1 was a host too. If that were the case, there wouldn't be much to do except get a different interface module, because it's a fundamental hardware difference. There's just no way an MSK 014 can be a "device" and talk to another host. Fortunately, it turned out there was something more complicated going on.
There's another layer to the USB standards in the shape of a protocol called "On The Go." On The Go is an optional extension under which some USB hardware can switch between being a device or a host. It involves special dual-function connectors so that an On The Go piece of equipment can connect to either a device or a host (using different cables, because non-On The Go hosts and devices have different connectors), or it can connect to other On The Go hardware, and the machines will automatically sort out between themselves who is the device and who is the host. If On The Go is supported at both ends, they can even switch roles back and forth while connected.
The OP-1 supports On The Go. The Gracious Host doesn't, but it shouldn't need to. If the OP-1 is following the rules properly, then it ought to automatically detect that the Gracious Host is host-only, and then the OP-1 should automatically become a device, allowing them to talk to each other. As far I could tell based on the blink code discussed below, that process was working correctly. The OP-1 was correctly being a device when it should, and the Gracious Host was detecting it as a device; just, an unknown device that it couldn't support. Why not?
Looking at the descriptors
USB is supposed to be hot-pluggable: you can insert and remove devices at any time, even while powered up. I remember hot-plugging Apple Desktop Bus devices (a predecessor to USB) on Mac computers back in the day, but you're not really supposed to do that because it can crash the computer. We can have an interesting discussion about whether it's okay to hot-plug Eurorack modules. I can't really recommend doing it, but I do it myself with the modules I sell because I know I can't stop customers from doing it and if a module is going to die, I want that to happen before I sell it, not after. With USB data storage in particular, it may be unwise to unplug a "key" while it's still in use by a computer. But the low-level USB protocol is designed around the concept that hot-plugging should work, and the designers of the bus put a lot of thought and care into that.
When a USB device is connected to a host, the host detects that the device has connected by the change in voltage levels on the bus, and then a complicated sequence of steps is supposed to unfold over the course of a fraction of a second. Part of this sequence is called "enumeration," in which the host assigns the new device a number with which the host will address that device for the rest of the time it's connected. In a bus with many devices, they're each given different numbers so that the host can communicate with them individually. With the Gracious Host in particular, because it doesn't support hubs and only talks to one device, it actually tells every device to be number 1, every time.
As another step, the host needs to figure out what kind of device it is talking to. That is accomplished using "descriptors." The device has a number of descriptors that explain what sort of device it is and how to talk to it, and the host makes a series of requests to the device asking it to produce those descriptors: "Tell me your device descriptor"; "tell me your configuration descriptor, number 1"; "tell me me your configuration descriptor, number 2"; "tell me your text descriptor, English language, number 46"; and so on. Some of the descriptors include reference numbers for other descriptors, and the host can pick and choose which descriptors to ask for in order to get the information it needs.
The specific complaint my customer reported was that when he plugged in the OP-1, the Gracious Host would blink one of its front-panel LEDs in a specific pattern, long-short-short.
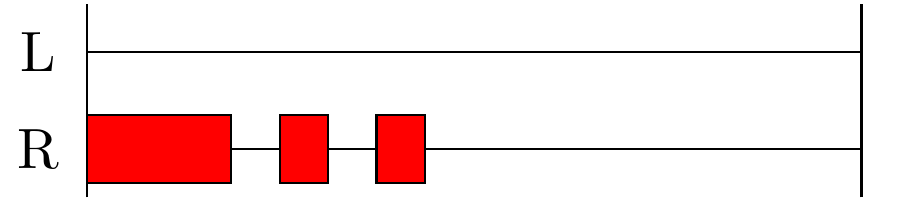
That is a Morse code "D," and as described in the user/build manual, the Gracious Host does that when it doesn't recognize a device.
The really interesting thing about getting the "D" blink code is that it means connecting to the device has been largely successful. The firmware only gets far enough to produce the "D" code if it has successfully detected the device; if the bus is not so overloaded as to trip the polyfuse; if it was a device (or, in this case, an "On The Go" thing correctly acting as a device); if the host has successfully enumerated the device and retrieved at least a few of the descriptors; but then if it somehow doesn't like those descriptors. In any other case, it would fail in some other way. Getting a blink code at all, also means there were no catastrophic build errors in this DIY module. The microcontroller is running, and it is executing at least something very close to the firmware it's supposed to be executing.
So, what was wrong with the descriptors?
On a Linux PC it is possible to type "lsusb -v" and get a detailed report of all the descriptors for all the attached USB devices. I discussed it with the customer, and I'm not actually 100% sure what he did - because I don't think he was running Linux - but by whatever means he managed to get a similar report for the OP-1, and sent it to me. At first glance, I couldn't see anything wrong.
How descriptors work
Descriptors are blocks of binary data that the host can request from the device. There are many different kinds of descriptors, and many extensions layered on top of the basic USB standards define new kinds of descriptors of their own. So it's entirely possible that a given device may have some descriptors that a given host hasn't seen before and doesn't understand. Nonetheless, as part of the "everything should just work" philosophy of USB, it's considered important for hosts to be able to pick out whichever parts they understand even when they can't understand every descriptor on the device. In order to support that, the first two bytes of each descriptor have a fixed format.
- The first byte of each descriptor says how long the descriptor is.
- The second byte of each descriptor says what kind of descriptor it is.
If the host is ever confronted by what I call a "pile" of descriptors (probably not the official name for this concept), then it can easily walk through the pile by following the length bytes from the start of each descriptior to the next, and at each descriptor it can recognize from the type byte what kind of descriptor it's looking at, then either parse the details of that particular descriptor using the known format for the type, or just skip to the next if it's an unknown type.
There is also an hierarchical structure to some of the most important descriptors. There's one device, with one or more configurations in it. Each configuration has one or more interfaces in it. Each interface has zero or more endpoints in it. And there can also be other things we don't understand. All these things have descriptors. The task of the Gracious Host firmware, when someone connects a device, is to go through the descriptors looking for an interface it can use (which necessarily would have to include endpoints of certain kinds), and choose the configuration containing that interface. It will give the "D" blink code if it sees some descriptors, but does not see descriptors on which it can successfully choose a configuration.
I won't reproduce the entire descriptor report for the OP-1, but here's a summary of what I saw when I first read it:
- Device (Teenage Engineering OP-1, 3 configurations)
- Configuration 1 (4 interfaces, requires 500mA power)
- Interface 0 (audio control)
- isochronous stuff
- Interface 1 (digital audio in)
- "alternate setting" stuff
- isochronous stuff
- isochronous data input endpoint
- Interface 2 (digital audio out)
- "alternate setting" stuff
- isochronous stuff
- isochronous data output endpoint
- isochronous "feedback" input endpoint
- Interface 3 (MIDI)
- MIDI configuration stuff
- bulk MIDI output endpoint
- bulk MIDI input endpoint
- Interface 0 (audio control)
- Configuration 2 (4 interfaces, requires 100mA power)
- identical to Configuration 1 except for the power requirement
- Configuration 3 (4 interfaces, requires 2mA power)
- identical to Configuration 1 except for the power requirement
- Configuration 1 (4 interfaces, requires 500mA power)
There are a lot of descriptors marked "isochronous stuff" above, which the Gracious Host cannot understand. But the point of the relevant USB standards is that it shouldn't need to. It ought to be able to go through the descriptors and find "Interface 3," the MIDI interface; select a configuration including that interface (which, indeed, they all do); and then speak MIDI to the OP-1. Why wasn't that happening?
I pored over the Interface 3 descriptor trying to figure out why the Gracious Host wasn't recognizing it. As far as I could tell, every relevant aspect of that descriptor matched the MIDI interface descriptors on other USB-MIDI devices with which I'd tested the Gracious Host firmware. If the host worked with other USB-MIDI devices, it should work with this one. There was nothing obviously wrong; but it wasn't working.
A wrong guess: power issues
If it works with other USB-MIDI devices and doesn't work with the OP-1, then the question is what's different about the OP-1, and I thought I found an answer to that. The OP-1 has three different configurations with three different stated power requirements, and that's not a situation I'd seen before on any of the other devices I had tested with.
In fact, during Gracious Host development I'd made the decision, which now looked like it might have been a mistake, to have the Gracious Host ignore stated power requirements entirely.
That wasn't just sheer irresponsibility. What I found during testing was that many devices lie about their power requirements, in either direction. At one early stage I thought I could just enforce a limit of 100mA on devices, but many devices people would reasonably want to use, would ask for more than 100mA. And many Eurorack installations have a lot of spare power available on the +5VDC bus, which is what supplies power to the attached USB device.
I designed the hardware with a 200mA polyfuse on the USB power supply. A device can draw up to that much indefinitely, and it can get away with drawing a fair bit more in brief spurts if they are not frequent, because the polyfuse takes some time to heat up before it trips. I was especially concerned about some USB flash memory devices which would declare their power requirement as 500mA (the maximum possible in basic USB, apart from special battery-charging extensions) but then would really only use a small fraction of that on average. I didn't want anyone to try to use one of those to flash replacement firmware, and be precluded from doing so.
It looked like Teenage Engineering had made trouble for me because they actually followed the rules properly: the OP-1 has three different power modes (probably corresponding to "charge your battery," "run on host power but don't charge the battery," and "run on battery power") and it was expecting the host to tell it, correctly, which one to use. The Gracious Host would choose the first configuration, the high-power one, by default because it ignored power requirements, and then the OP-1 would draw too much power and trip the polyfuse.
Except, wait a minute. It didn't trip the polyfuse! If it had, that would have been a totally different blink code and might have taken down the entire Eurorack bus. Instead it was just quietly blinking "D" with no other issues.
Nonetheless, it seemed like I couldn't justify anymore the original decision to ignore power requirements. I gave it some thought and came up with a solution that should work with both correctly-implemented devices like the OP-1, and the incorrectly-implemented devices with unrealistic power requirements I'd tested earlier.
Because of some technical aspects of how the Gracious Host examines descriptors, the original firmware needed to make a yes/no decision on each configuration descriptor before it could even look at the next configuration descriptor. It was a little bit like the buzzard in the story, who was allowed to try on every suit of feathers but not allowed to go back to one he'd tried after he chose to take it off and try another, so he tried them all and was stuck with the last one, which was too small and left his bare head hanging out.

The Gracious Host would instead settle for the first interface that seemed like it might work. The requirement not to go back after choosing to pass up a configuration or interface came about because the microcontroller doesn't have much memory and cannot store the entire set of descriptors all at once to make multiple comparisons among them. Then saying "no" to a configuration because it required too much power would be a problem, because there might not be any better configuration coming later.
I changed the firmware to make two passes through the list of configurations. On the first pass, it would accept the first usable configuration requiring less than 210mA of power (the 200mA limit of the polyfuse, plus a bit of tolerance). But then if it went through all the configurations without finding one it liked, it would make a second pass with the power limit removed. For a device like the OP-1 which had multiple configurations, some usable and some not, correctly marked with their power requirements, this design would choose the first one within the power limit. But for a device like the no-name flash keys I was testing earlier, with incorrectly declared power requirements all of them over the limit, it would choose the first one and take its chances - because failing to choose at all would be worse than tripping the polyfuse or overloading the bus.
I planned to send the updated firmware to the customer to try, but I wasn't at all confident that it would really solve the problem because of the polyfuse issue. If power were really the problem, then the module ought to be succeeding at the configuration step and then tripping its polyfuse when the OP-1 drew too much power, and that was not actually what was happening. Instead, it was failing at the configuration step, and not tripping the polyfuse. I thought the power-limit handling represented a firmware bug that should be fixed, but it seemed clear that that wasn't really the cause of the customer's observed problem.
I needed more information about what was actually happening inside that module when the OP-1 connected. Ideally, I would hook up a debugger to the module and single-step the firmware while connecting an OP-1. But I didn't have an OP-1 in my lab, and couldn't easily lay hands on one. They cost about US$2000 each to buy, and wouldn't be cheap to rent either, and as mentioned, I can't afford to spend more money on MSK 014 development at this point. So I had to depend on tests the customer could perform, and report the results back to me.
Exfiltrating debug information
I started adding blink codes to the firmware: instead of just blinking a Morse "D" when it failed to choose a configuration, I thought I could make it blink different codes depending on why it failed. Ideally, I would have liked to get what I'd get from an in-circuit debugger (such as I would use in my own lab): that is, the complete history of the code path the microcontroller followed before it determined it could not proceed.
That's a lot of information to exfiltrate through the front-panel LEDs, especially given that I would need my customer to either read the codes by eye, or record a video of them to send to me. I couldn't reliably expect to get a report distinguishing between more than about eight different codes (that is, three bits of information) and since I didn't even know exactly what information I needed, because I had no solid clue of what might be going wrong, it was hard to design a set of codes and hook them into the firmware in a way that would help.
I didn't want to get into an endless cycle of sending experimental firmware images to the customer and asking for reports of the blink codes that might result. After some local experiments, I decided that I needed a way of getting back much more data in a single report. What would be a higher-bandwidth way of getting information from the module, to me?
The answer was audio. I added some code to the firmware so that when it failed to choose a configuration for the USB device, then while displaying the existing "D" blink code it would also modulate its entire memory contents into an audio signal and produce that on the front-panel jacks. Then I could ask the customer to record the audio and send me a WAV file, from which (I hoped) I could decode the memory contents and figure out what was going on with that microcontroller when the OP-1 connected.
This is kind of like what people do to debug spacecraft, and just like with spacecraft, there's not a lot of room for making mistakes. Above all it would be important that the experimental firmware shouldn't "brick" the module. Also, the signal it produced should be more or less impervious to noise, because it might not be possible to get a clean recording of it. But any complicated error-correction would have to be limited by both the microcontroller's capabilities, and the amount of programming effort I was willing to put in. It might not be worthwhile for me to spend days writing a complete implementation of a state-of-the-art error-correcting code when it would only be used just this once. If ever there would be a tradeoff between complexity on the transmitting end and complexity on the receiving end, it would make sense to do the extra work on the receiving end, because that would be on my own local computer and I would have the chance to make multiple tries. Repeat attempts at the sending end would be much more costly.
I didn't know just what data I would need to see in the memory, because I really didn't know what was wrong in the first place, hence the plan to dump the entire memory contents and just hope I could find something helpful in there. And I wanted to get all this right on the first try.
With all that in mind, here are some notes on the transmission format I designed. There is more detail in the MSK 014 programmer's manual, because I've subsequently incorporated a cleaned-up version of this debugging code into the stock firmware.
Error-correction code
Suppose I'm trying to transmit an eight-bit byte over some kind of electronic signal path.
1 0 0 1 1 1 0 1
A random pulse of noise might cause one of the bits to be incorrectly received: where I transmitted a 1 the receiver might pick up a zero, or vice versa.
1 0 0 1
11 0 11 0 0 1 0 1 0 1
That's a problem.
One thing that might be done about it, would be to transmit a ninth bit, which will be called the parity bit. The parity bit is the XOR sum of all the data bits (other schemes are possible; I am describing a popular one). So if there are an even number of 1 bits among the data bits, then the XOR sum is 0, and if there are an odd number of 1 bits, the XOR sum is 1. Overall, counting both the data bits and the parity bit, there are always an even number of 1 bits transmitted.
1 0 0 1 1 1 0 1 1
Then if exactly one of the bits is flipped by noise, the "always an even number of 1 bits" property ceases to be true; and the receiver will know there's been an error in transmission.
1 0 0 1
11 0 1 11 0 0 1 0 1 0 1 1 - ERROR, odd number of 1s
This error-detection scheme (single even parity bit) was used on some lower-speed dialup modem connections in the 1980s and 1990s, and prior to that in teletype systems.
With a single parity bit, all the receiver knows when the check fails is that there has been one bit (or three, or some odd number of bits) flipped in transmission. Single-bit parity doesn't say which bit is wrong except that it's somewhere in this byte, so it only helps to detect errors, not really to correct them. Also, it will fail to detect errors if there happen to be an even number of errors, such as two. It's hardly a complete solution to the problem of errors. But it's a start, and it's a clue to an important insight: I can gain some protection against errors by transmitting extra bits in among my data bits, and then doing processing at the receiving end to determine what happened during transmission. Maybe if I'm transmitting data bits out of the Gracious Host, I should insert some parity bits so that I can tell when there are occasionally bits flipped by noise; and maybe this scheme can be carried further.
What if I use more parity bits? Just transmitting a single, overall parity bit more than once isn't going to help a lot. At best, if I send two copies of the parity bit then the receiver can check whether they match, and know if they don't that at least one of them must have been corrupted. But that doesn't really have much advantage over just sending the single overall parity bit.
Here's a more complicated scheme. Suppose I send some number of data bits, and some number of parity bits, in such a way that every data bit is covered by at least two of the parity bits, and also, every data bit is covered by a different combination of parity bits. For example, I might use four data bits and three parity bits.
1 0 0 1 0 0 1
a b c d x y z
x = a XOR b XOR d
y = a XOR c XOR d
z = b XOR c XOR d
If any one data bit gets flipped in transmission, then at least two of the parity bits will appear wrong when the receiver checks them, because every data bit is included in two or more parity bits. Also, unlike with simple one-bit parity, when we detect that a single data bit was flipped, we know which one it was; because every data bit is included in a different combination of parity bits. And so we are not just limited to knowing "there was an error"; we can actually determine which bit was flipped and flip it back, recovering all four data bits correctly despite the error. For completeness, note that if a single bit gets flipped in transmission and it happens to be one of the parity bits, then when the receiver checks the parity bits it will only detect one of them failing, which could not happen on a data bit flip, so it can conclude that the error was in the parity bits and not the data bits.
The above scheme is called the Hamming(7,4) code, and it's one of the simplest error correcting codes. If any single bit in the seven-bit code word gets flipped by an error, then the Hamming(7,4) code can not only detect the error, but correct it.
This code originates in work by Richard Hamming on error correction in relay-based computers at Bell Labs, first published in 1950.
It's fairly easy to verify that four data bits are the maximum number of data bits that could be covered by three parity bits in this kind of scheme. With three parity bits there are eight different subsets possible, then we subtract one for the empty subset and three more for the subsets of size one, and that leaves 8-1-3 = 4 subsets of two or more parity bits, with each data bit using a different one of them.
Doing the correction requires making an assumption that there really was at most one bit flipped. Suppose instead of one bit getting flipped in transmission, two are, and they happen to be two of the parity bits. Then the receiver might conclude that one of the data bits (indicated by the two failing parity bits, but actually having its correct value already in this scenario) must have been corrupted, and mis-correct that data bit.
But we can go a little further by adding one more bit, an overall parity bit covering all the data and other parity bits. In that case, we can tell the difference between "one bit flipped, parity bits tell us where" and "two bits flipped" because a single bit flip will break the overall parity check and a double bit flip won't. The resulting code with four data bits and four parity bits is sometimes called an "extended" Hamming code, or a SECDED code, for "single error correcting, double error detecting." Given the assumption of no more than two errors, we can correct any one error or, when there are two, at least know that there were two errors without being able to correct them. The extended Hamming(7,4) code is used in some ECC memory for desktop and server computers today.
For the Gracious Host memory dump, I decided to use an extended Hamming(15,11) code. That is much like the smaller code above, just extended to more bits: there are four main parity bits, covering 11 data bits, plus an overall parity bit, for a total of 16 bits in the code word. Given the assumption of no more than two errors in the code word, it can correct any one bit error or detect any two bit errors.
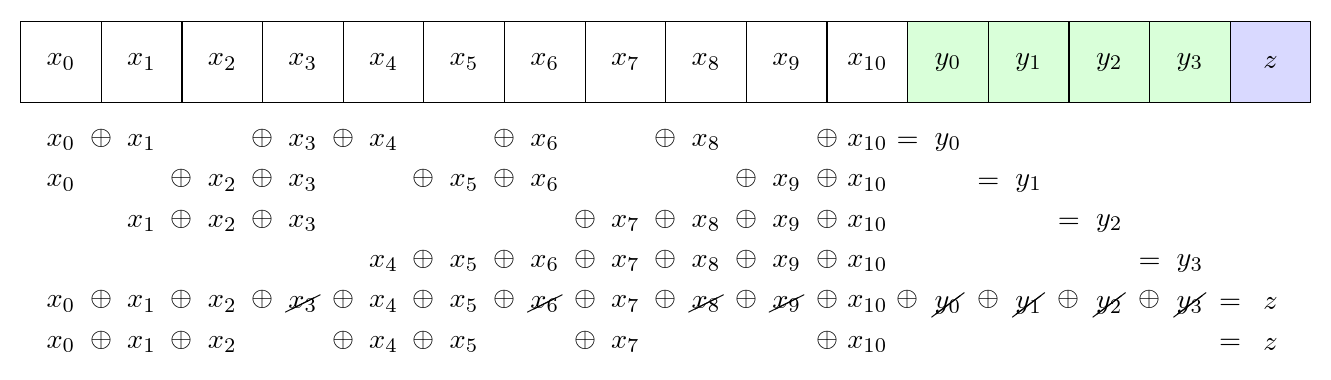
When the firmware decides to initiate a memory dump, it starts looping over 256-byte blocks in the microcontroller's RAM (total RAM capacity 8K, so there are 32 of these). To each 256-byte block, it prepends 8 bytes of metadata (four bytes of filler, and the values of two 16-bit machine registers). That makes the size of the block 264 bytes, which is a multiple of 11. So then it has 24 chunks of 11 bytes each, each of which is extended to 16 bytes by the extended Hamming(15,11) code. It does the XOR operations byte-by-byte, so that the code is being evaluated in parallel at each of the eight bit positions in the bytes.
The extended Hamming error-correcting code may sound complicated, and it may well have been overkill for this application. But I find this kind of thing interesting, and I really didn't want to have my data corrupted by noise. Although actually doing the error correction at the receiving end might become complicated, note that the transmission logic for this is simple, and as I said, there was some priority on having the transmitter be simple even if the receiver would be complicated. The transmitter is just rearranging bytes and then XORing them in a fixed pattern. That was easy to implement as a modification to the existing Gracious Host firmware, and it's only a page or so of assembly code in the firmware source, which you can download from the "Resources" section at the bottom of the storefront page for the module. Implementing the Hamming code step itself was not much work; documenting it took much longer.
Hamming codes, although powerful, are far from the last word in high-tech error correcting codes. I was really tempted to go further and implement a Reed-Solomon code, dating from 1960 instead of 1950, which would allow tunable levels of error correction beyond one error per code word. In very rough terms we might say that whereas the Hamming code is linear, and it only uses XOR which is kind of like addition when you squint hard, the Reed-Solomon code is based on higher-order polynomials, and uses a thing that is kind of like multiplication as well as addition. But using Reed-Solomon would have required me to implement and test finite field arithmetic on the microcontroller, at a cost of at least another day of work, probably two. I couldn't justify spending that time given that this piece of software would probably only ever really be used once.
Bit interleaving
The extended Hamming(15,11) code can correct one error in each 16-bit code word, so it should be able to correct all the errors in transmission even if they amount to 1/16 of the bits, that is, 6.25%. Right?
Not quite so fast. The code can correct one bit error per code word, but only if the errors really are spread out over the code words that way. In practice, 100 code words will not have one error each; instead there may be a burst of 100 errors that obliterates a few code words entirely, and the rest remain untouched. The error correction code cannot repair that kind of damage.
The fact that we are evaluating the XOR at the level of bytes already provides some protection against noise bursts, and a clue to what more we can do. If a noise burst takes out three or four bits from a single byte, those will be in different bit positions, with a separate code word for each bit position, and so the burst will really hit three or four code words once each (correctible) instead of a single code word three or four times (not correctible). Working on bytes instead of bits has the effect of interleaving eight copies of the code, spreading out consecutively-transmitted bits into separated code words.
When the firmware prepares to send a block of data, it is already building a conceptual matrix of 24×16 bytes in memory. Memory data fills the first 11 columns of that matrix and the remaining five contain error correction information, writing each code word left to right along the rows.
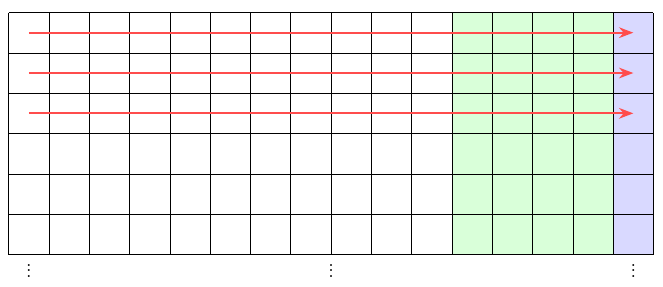
But when it actually transmits the block, it reads the matrix in transposed order, top to bottom along each column. It transmits the first byte of each row (24 bytes in all) before it starts transmitting the second byte of each row, and so on.
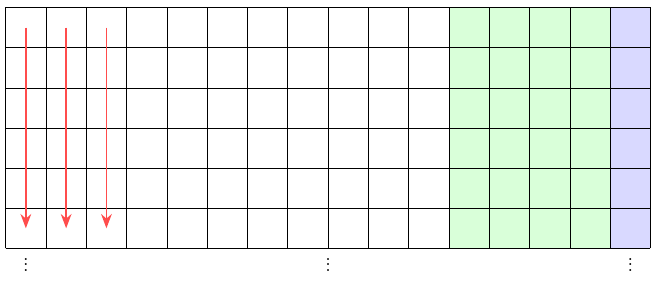
If a noise burst takes out a number of consecutive transmitted bits, it needs to be more than 192 bits long in order to hit the same code word more than once. Then it's much more possible for the error correcting code to come close to its theoretical limits in practice, where noise tends to come in bursts. And this interleaving technique is another easy one to implement in the firmware, because it only comes down to reversing the order of the loops that iterate over the bytes in memory.
Differential Manchester encoding
The extended and interleaved Hamming code produces a string of bits, but there is still some question of how to transmit those bits in a way that will survive being recorded as audio. The obvious serial transmission method is to just choose two voltages and a clock rates: for a 1, send something like +5V for some fixed length of time, for a 0, send 0V for the same length of time, and just iterate through all the bits.
There are multiple problems with that approach, all of which have to do with the idea that the output voltage may stay in one state for an extended period of time. If there are five or six 1s in a low, the voltage stays at +5V for five or six bit times. The receiver needs an accurate and well-synchronized clock to be sure of whether the transmitter intended that to really be five, or six.
As well as time, there can be issues with the voltage when it stays fixed for a while. If the audio signal goes through an AC coupling capacitor, which often happens to audio signals, then a string of consecutive unchanging 1 or 0 bits will look like DC and be blocked, making it hard for the receiver to accurately track the original voltage. And it's also common for audio signals to end up inverted, so the receiver may not know which voltage the transmitter intended to be more positive; all the 0s could be turned into 1s and vice versa. It's even possible that as a result of filtering in transmission, an audio signal may be inverted or not, or parts of it inverted or not, depending on frequency, which would cause even more confusion.
The overall picture is that we want to make sure the output voltage will change regularly even if the bits don't. There needs to be a timing reference that can keep the transmitter and receiver clocks synchronized, and we want to have the receiver look for features of the signal that will probably survive audio transmission (like timing of edges) rather than features that will probably be destroyed in the signal chain (like exact voltages).
I decided to encode the bits into voltages using a technique called "differential Manchester encoding." It is also often called "FM," but that abbreviation has so many other meanings in the synth world already that I think "differential Manchester" is clearer. This technique was used on early digital magnetic recording media, like "single-density" floppy drives, before being supplanted by more complicated encodings with higher performance. The name refers to Manchester University and their "Mark 1" computer in 1949-50, which used an earlier, non-"differential," encoding for its magnetic drum memory.
The rules for differential Manchester encoding are simple:
- The voltage toggles at the start of each bit time.
- In the case of a 1 bit (only), the voltage also toggles in the middle of the bit time.
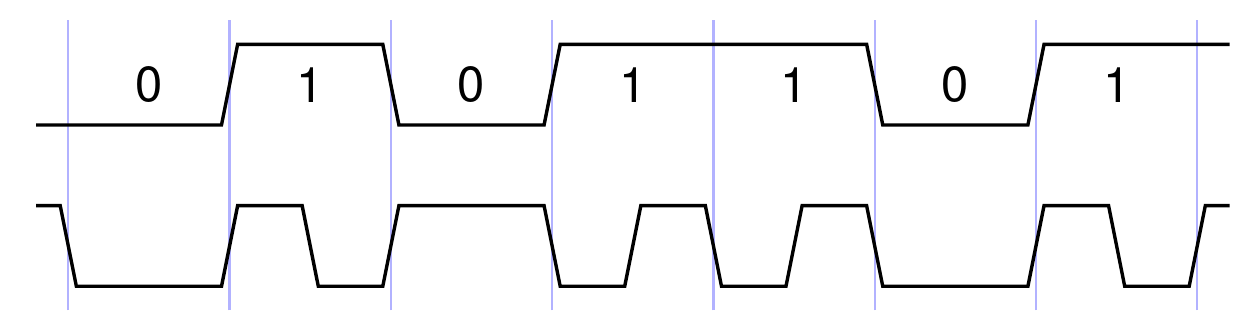
This encoding guarantees at least one bit transition, and no more than two, per bit time regardless of the contents of the data being transmitted. It's reasonably easy for a receiver to lock onto the timing of the signal even when that timing is distorted a little by the effects of a transmission channel. It has the desired property of not depending on the specific voltages or which one is high and which one is low.
I chose to use a target of about 272µs per bit, which comes from estimating that 12 samples of audio per bit at 44.1kHz sampling would be a convenient rate to decode. It works out to about 3.7kbps - for the fully encoded data with error-correction overhead, so the actual rate of transmitting memory contents is a bit slower, and the complete dump of 8K of memory data ends up taking about 27 seconds. The debugging firmware just keeps cycling around the blocks, inserting a few milliseseconds of silence between them for synchronization, repeating the complete dump as long as the unrecognized USB device remains plugged in.
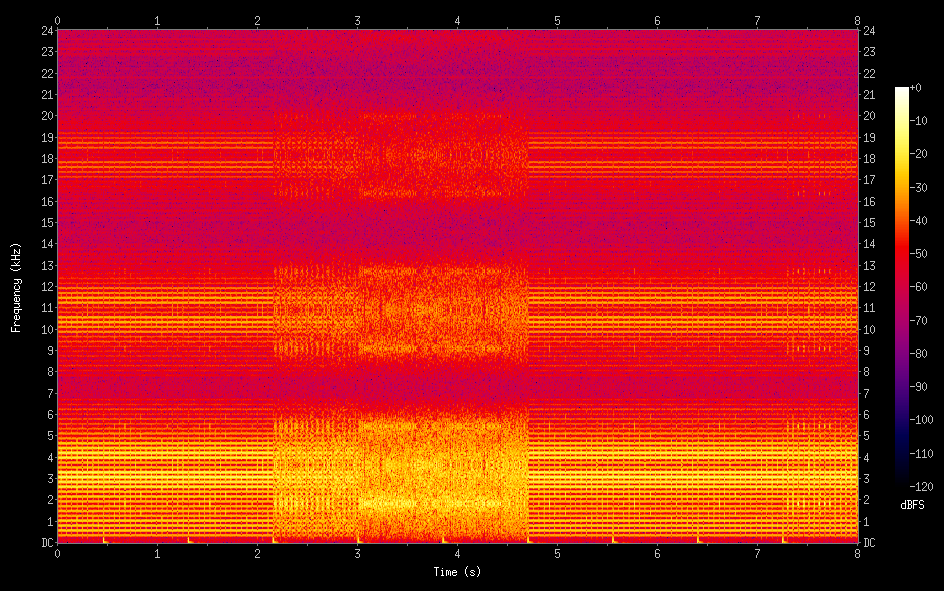
Here's a spectrogram of a clip from the memory dump signal, and an audio version (which is loud and annoying). You can see and hear the change in texture as the dump covers different regions of memory: some parts of the memory space are empty, giving a repetitive pattern of fixed tones, and others contain live data that sounds like noise. In the spectrogram you can also see the null around 3.7kHz for the bit rate (which is like a carrier), and its third and fifth harmonics. Since it is in the nature of a square wave, the carrier ends up with only odd harmonics.
The culprit revealed
I sent the memory-dump firmware to the customer, who collected a recording of the signal and sent it back to me, and upon analysis of that, it seemed I might have way overengineered the error correction code; because the recording was so clean that there were no errors to correct in the first place. I was able to decode it all without using any of the parity bits. But, of course, I didn't know the recording would be so clean when I was preparing the memory-dump firmware.
The one thing I most wanted to see was the descriptor the firmware was looking at when it decided it couldn't go on. I had a tentative idea that maybe there was something wrong with the MIDI interface descriptor such that the Gracious Host firmware couldn't locate the necessary endpoints. I couldn't think what might be wrong with the MIDI descriptor - it seemed just the same as other MIDI descriptors on other devices that worked - but I thought maybe seeing the binary data of the descriptor in the memory dump would offer a useful clue.
When I found the descriptor on which it failed, it was clear that that wasn't the problem, because the Gracious Host was blowing up on one of the isochronous descriptors in interface 2. It should have been reading those but skipping them, because it doesn't understand isochronous interfaces. So what was going on?
Here's a summary of the descriptors, with just a little more detail than before:
- Device (Teenage Engineering OP-1, 3 configurations)
- Configuration 1 (4 interfaces, requires 500mA power)
- identical to Configuration 3 except for the power requirement
- Configuration 2 (4 interfaces, requires 100mA power)
- identical to Configuration 3 except for the power requirement
- Configuration 3 (4 interfaces, requires 2mA power)
- Interface 0 (audio control)
- isochronous stuff
- Interface 1 (digital audio in)
- "alternate settings" will follow
- Interface 1, alternate setting 1 (digital audio in)
- isochronous stuff
- isochronous data input endpoint
- Interface 2 (digital audio out)
- "alternate settings" will follow
- CONFIGURATION ABORTS HERE
- Interface 2, alternate setting 1 (digital audio out)
- isochronous stuff
- isochronous data output endpoint
- isochronous "feedback" input endpoint
- Interface 3 (MIDI)
- MIDI configuration stuff
- bulk MIDI output endpoint
- bulk MIDI input endpoint
- Interface 0 (audio control)
- Configuration 1 (4 interfaces, requires 500mA power)
Do you see the trap in the descriptor pile?
Each configuration says it contains four interfaces. But each configuration actually contains six interface descriptors, because some of the interfaces have "alternate settings" which are implenented as additional descriptors for the same interface number. The "alternate settings" concept is one of many things that the Gracious Host is intended to ignore because that's primarily relevant for digital-audio devices, which the Gracious Host isn't meant to support.
So the firmware is reading the configuration descriptor which says four interfaces, and then it reads forward until it has seen four interface descriptors in the configuration, and then it stops, never having seen an interface it likes. It repeats this for each configuration, failing on each one, eventually stopping on the last configutation. The basic problem is that the firmware is assuming an equality between interfaces and their descriptors, which is true for most devices but not the OP-1.
The problem went unnoticed until someone tried to connect an OP-1 because the "alternate settings" concept is not frequently used; and even if a device might use "alternate settings," it wouldn't be a problem for the original firmware unless the Gracious Host happened to be looking for a desired interface that happened to come after an interface with "alternate settings" within the same configuration, which is not necessarily a common situation.
The solution was to adjust the loop counter on each "alternate setting" interface descriptor so that it wouldn't count toward loop termination. Only the "main" interface descriptors count toward loop termination, so the firmware should see all four interfaces when there are four interfaces, even if those four interfaces have among them six or more descriptors.
I put together a new test version of the firmware with the loop counter fix in place and some refinements to the memory-dump procedure in case it didn't work (the encoding described here is actually the final version; the first was less polished) and sent that off to the customer and, fortunately, it worked with the OP-1.
Problem solved, for that one support case anyway.
I subsequently released a new "standard" firmware version incorporating the two fixes (power limit and "alternate settings"), and posted it on the storefront page. If you have a Gracious Host and want to have the latest and greatest firmware, you can download that and install it via the procedure explained in the manual. Doing the update will require re-doing the calibration (as also explained in the manual). On the other hand, if your module is already working well, you may not have any reason to need a firmware update.
◀ PREV Carmilla || AoC 2024 in ECLiPSe-CLP NEXT ▶

MSK 014 Gracious Host
US$244.68 including shipping
Comments
Also, great website implementation to not throw away my comment when I failed the Anti-spam test...
The idea of making it more "musical" raises an interesting artistic question: can we compose music that simultaneously works as music, and will carry some important message when decoded as a QPSK (or other similar) digital signal? This could be the new back-masking!